
Natürlich können wir an dieser Stelle nicht auf die technischen Details und die Programmierung von Algorithmen für KI-Anwendungen eingehen. Das würde den Rahmen dieses Blogbeitrags sprengen, aber es soll doch der Versuch unternommen werden, die Funktionsweise von KI ansatzweise zu verstehen. Die gebräuchliche auf Software basierende KI beruht auf der Aussagenlogik.1 Jede Aussage kann wahr oder falsch sein. Die Aussage „heute scheint die Sonne“ lässt sich leicht durch den Blick aus dem Fenster verifizieren oder falsifizieren. Für eine digitale KI nimmt die Aussage den Wert 1 an, wenn die Sonne scheint (wahr) oder den Wert 0, wenn sie nicht scheint (falsch). Aussagen lassen sich einfach mathematisieren und mit UND, ODER und mit WENN-DANN-Regeln verknüpfen. Letztere sind die Grundlage für jeden Algorithmus, der da lauten könnte: „WENN die Wassertemperatur im Kessel auf 80° Celsius ansteigt, DANN schalte die Heizspirale ab.“ Mit diesen Verknüpfungen lassen sich sehr komplizierte Aussagenketten erstellen, mit denen die KI arbeiten kann.
Auf diese Weise denkt eine KI und kann Schlussfolgerungen ziehen und Vorhersagen machen. Sie kann es aber nur aufgrund von mathematischen Berechnungen, die auf einem Regelwerk beruhen. Das Regelwerk, mit dem die KI die Aussagen korrekt kombiniert, wird auch Syntax genannt. Sie ist die Grammatik, mit der die KI lernt, richtige Aussagen abzuleiten. Den Inhalt der Aussage, die Semantik, kann die KI aber nicht verstehen. Sie arbeitet lediglich Inputinformationen nach vorgegebenen Regeln ab und erzeugt daraus einen Output, ohne zu verstehen, was sie tut.2
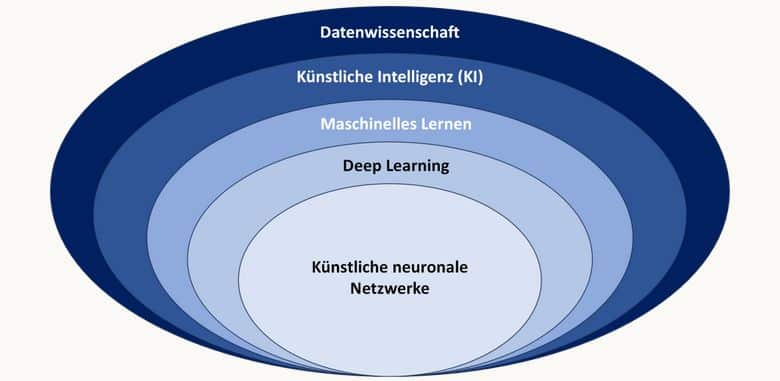
Damit die KI ihre Aufgabe erfüllen kann, benötigt sie riesige Datenmengen, auch Big Data genannt, in der sie verborgene Zusammenhänge aufdecken kann. Die KI ist daher ein Teilgebiet der Datenwissenschaften, die sich an der Schnittstelle von Informatik, Mathematik und Statistik mit der Gewinnung von Wissen aus großen Datenmengen beschäftigt. Ein Teilgebiet von KI ist, wie wir bereits gesehen haben, das maschinelle Lernen. Im Gegensatz zum Programmieren geht beim maschinellen Lernen nicht darum, auf einen gesammelten Datensatz einen programmierten Algorithmus anzuwenden, um dann einen bestimmten Output zu erzielen, sondern das KI-System wird mit einem Datensatz und dem dazugehörigen Output gefüttert und der Computer lernt, indem er einen Algorithmus generiert, der eine Beziehung zwischen Datensatz und Output herstellt.3
Abbildung xx: KI, maschinelles Lernen und Deep Learning
Maschinelles Lernen kann in überwachter Form stattfinden, nicht überwacht oder in einer Mischform des teilüberwachten Lernens. Das überwachte maschinelle Lernen (supervised learning) basiert auf markierten bzw. gelabelten Daten, für die sowohl der Input- als auch der Outputwert bekannt sind. Die Daten müssen vorab von Menschen gelabelt werden, damit das KI-System damit trainiert werden kann. Auf dieser Basis kann die künstliche Intelligenz Muster und Beziehungen in den Daten herstellen und Vorhersagen treffen. Zu diesem Zweck wird das Datenset in drei Subsets für Training, Validierung und Testung aufgeteilt. Der Trainingsdatensatz wird dazu verwendet, dem KI-System zu zeigen, wie die Input- und Outputdaten zusammenhängen, was in einer mathematischen Funktion dargestellt werden kann, aus der der Lern-Algorithmus4 abgeleitet wird. Der so erlernte Algorithmus wird nun auf den gesamten Trainingsdatensatz angewendet. Die Ergebnisse werden mit den Parametern aus dem Validierungsdatensatz abgeglichen und angepasst. Wie gut der Lern-Algorithmus funktioniert, wird dann anschließend am Test-Datensatz, der vom Trainingsdatensatz getrennt ist, gemessen. So lernt das KI-System den Algorithmus an Veränderungen anzupassen und Hypothesen über den Outputwert zu bilden. Als überwacht wird der Lernprozess deshalb bezeichnet, weil die Ergebnisse, die der Algorithmus erzeugt, stets mit den korrekten Ergebnissen aus dem Test-Datensatz verglichen werden.5
Beim unüberwachten Lernen (unsupervised learning) sind die korrekten Outputwerte nicht bekannt und so kann es auch keinen Trainingsdatensatz geben, aus dem der Lern-Algorithmus abgeleitet werden kann. Ein Markieren der Daten ist beim unüberwachten Lernen nicht vonnöten. Stattdessen erkennt der Algorithmus im Datensatz Strukturen, die durch statistische Verfahren wie Varianz- oder Clusteranalysen erzeugt werden. Kommt ein neuer Datensatz hinzu, so kann das KI-System auf den Ergebnissen früherer Analysen aufbauen und den Algorithmus weiterentwickeln.6 Beim teilüberwachten Lernen (semi-supervised learning) werden beide vorher genannten Methoden verknüpft, sofern der Datensatz es erlaubt und bestimmte Zusammenhänge zwischen Input- und Outputdaten vorab bekannt sind.7 Der Vorteil besteht darin, dass weniger Daten für das KI-Training benötigt werden, wodurch die Trainingszeit abgekürzt werden kann.
Neben dem überwachten und nicht-überwachten Lernen ist das Reinforcement Learning oder be- bzw. verstärkendes Lernen die dritte wichtige Ausformung maschinellen Lernens. Dabei erlernt das KI-System eine Strategie, um erhaltene Belohnungen zu maximieren und Strafen zu vermeiden. Das KI-System steht dabei in Verbindung mit seiner Umwelt und lernt durch Feedback, wie es sich verhalten soll.8 Es gibt also nicht nur eine korrekte Lösung für ein Problem, sondern eine Vielzahl von Lösungen, die durch Versuch und Irrtum getestet werden, bis die beste Lösung gefunden wird.
Klassisches maschinelles Lernen wird dort eingesetzt, wo Probleme klar strukturiert sind und sich mathematisch-statistisch gut abbilden lassen. Diese Probleme sind für den Menschen intellektuell schwer zu verarbeiten, können aber von Computern rasch und effizient gelöst werden – man denke nur an die Robotik. Komplizierter wird es dann, wenn Probleme von Menschen leicht mithilfe der Intuition zu lösen sind, aber schwierig in mathematische Regeln gefasst werden können, damit sie Maschinen anwenden, wie das bei der Sprach- und Bilderkennung der Fall ist. Damit auch solche schlecht strukturierten Probleme von Maschinen bewältigt werden können, wurden künstliche neurale Netzwerke (KNN) entwickelt,9 die aus Knoten (Neuronen) bestehen, die miteinander kommunizieren. Ein solches KNN ist dem menschlichen Gehirn nachempfunden, in dem Synapsen miteinander über Neuronen Informationen austauschen. Die Pendants in den KNN sind Lern-Algorithmen, die als Perzeptronen bezeichnet werden, die mehrere Inputfaktoren (Eingangsschicht) über eine Vielzahl nicht sichtbarer Schichten (hidden layers) mit Outputfaktoren (Ausgangsschicht) verknüpfen. Ein solcher mehrschichtiger Perzeptronen-Algorithmus bildet das künstliche neuronale Netzwerk (KNN). Durch ihre Schichtung können die Algorithmen sich an neue Inputs passen und daraus lernen. Künstliche neuronale Netzwerke können entweder überwacht sein, d.h. die Input- und Outputbeziehung ist bekannt und jeder vorhergesagte Outputwert wird mit einem bekannten Outputwert verglichen oder sie sind nicht-überwacht, weil die Input- und Outputbeziehung unbekannt ist und der Algorithmus im Datenset Strukturen erkennen muss, um daraus zu lernen. Auch das verstärkende Lernen ist möglich, indem der Algorithmus ein Ziel verfolgt, das er in einem Trial- und Error-Verfahren in Interaktion mit der Umwelt zu erreichen versucht. Ein solches künstliches neuronales Netzwerk wird im Englischen auch als Reinforced Neural Network (RNN) bezeichnet.
Maschinelles Lernen mithilfe von KNN und RNN wird deshalb als Deep Learning bezeichnet, weil die Schichten zwischen Eingangs- und Ausgangsschicht so komplex miteinander interagieren, dass ein menschlicher Bediener nicht mehr in der Lage ist nachzuvollziehen, wie die Lernprozesse der KI ablaufen.10 Ein Deep-Learning-Algorithmus kann also Aufgaben ausführen, indem er aus großen Rohdatenmengen Informationen neu arrangiert und strukturiert. Der Unterschied zum klassischen maschinellen Lernen besteht aber nicht nur in der verwendeten Datenmenge, die wesentlich größer ist und in unstrukturierter Form vorliegt, sondern auch in der Informationsextrahierung. Beim maschinellen Lernen braucht es einen Menschen, der dem KI-System Anweisungen gibt, welche Informationen gewonnen werden sollen, wohingegen beim Deep Learning das KI-System selbst darüber entscheidet, welche Informationen wichtig sind und welche nicht.11
Um das besser zu verstehen, wenden wir uns einem Beispiel der Bilderkennung zu. Die KI wird mit Bildern z.B. von Katzen trainiert, d.h. die Eingangsschicht des neuronalen Netzes verarbeitet die Rohdaten in Form von Millionen Pixeln mit Merkmalen einer Katze, die ihre Outputwerte in einem Zahlenformat an die nächste Schicht weiterleitet und diese wiederum an die nächste Schicht und so weiter und so fort. Die Werte in den verborgenen Zwischenschichten (hidden layers) werden von Verarbeitungsschritt zu Verarbeitungsschritt abstrakter und können nicht mehr auf die Eingangsdaten zurückgeführt werden. Es muss also das KI-System selbst bestimmen, wie die Beziehung zwischen den beobachteten Daten zu erklären ist und welches Ergebnis als Output in der letzten Schicht ausgegeben wird. Dadurch ist es auch für die das System bedienende Person nicht mehr möglich nachzuvollziehen, wie die KI zu einem bestimmten Ergebnis kommt und eine Katze als solche identifiziert.12
Gerade in der Bilderkennung braucht es noch eine spezielle Methode, um verlässliche Ergebnisse zu erhalten. Es ist nämlich sehr schwierig, einer KI beizubringen, die Merkmale, die eine Katze ausmachen aus der riesigen Menge von Bildern, mit der sie gespeist wird, herauszufiltern. Deshalb wurde dazu übergegangen die Eingangsschicht einer KI mit einer großen Anzahl von Filtern zu versehen, die jeweils nur kleine Ausschnitte eines Bildes analysieren und eine Wahrscheinlichkeit für ein konkretes Merkmal einer Katze berechnen. Diese Wahrscheinlichkeiten werden nun von einer hierarchisch übergeordneten Schicht des neuralen Netzes ausgewertet und zu komplexeren Merkmalskombinationen, die ein Katze ausmachen, verknüpft. Dieser Prozess kann über zahlreiche hierarchische neuronale Ebenen fortgesetzt werden, bis eine KI nicht nur in der Lage ist, eine Katze von einer Nicht-Katze zu unterscheiden, sondern Katzenrassen zu differenzieren. Wichtig ist zu verstehen, dass die KI selbst entscheidet, welche Merkmale eine Katze ausmachen. Künstliche neuronale Netzwerke, die in dieser Form hierarchisch angeordnet sind, werden als Convolutional Neural Networks (CNN) bezeichnet, weil die Knoten im Netzwerk sogenannte Faltungsfilter (convolutional filters) sind.13
Egal ob jetzt KNN, RNN oder CNN in KI-Systemen zum Einsatz kommt, wichtig ist zu verstehen, dass alle diese Formen des Deep Learnings nicht mehr nachvollziehen lassen, wie die KI aus Inputfaktoren einen Output erzeugt. Das Lernsystem ist komplex und das Ergebnis kann nicht mehr vorhergesagt werden. Ist das Ergebnis ein Musikstück, dann kann es durchaus als kreativ bezeichnet werden, auch wenn die KI es nur pseudokreativ erzeugt. Wir wollen nun in weiterer Folge frühe Anwendungsgebiete Algorithmen-basierter Datenverarbeitung im Musikbusiness wie die Musikerkennung, Musikempfehlung und die Rolle der KI im Musikstreaming genauer beleuchten.
Peter Tschmuck
Dieser Artikel erschien erstmal am 15. Jänner 2024 auf der Seite https://musikwirtschaftsforschung.wordpress.com/2024/01/22/ki-in-der-musikindustrie-teil-2-wie-funktioniert-kunstliche-intelligenz/#more-5276
Teil 1: Was ist künstliche Intelligenz?
Teil 3: Der Aufstieg von Musikerkennungsdiensten
Teil 4: KI in der Musikerkennung und Musikempfehlung
Teil 5: Die Musikempfehlung im Musikstreaming
Teil 6: Fake-Streams und Streamingfarmen
Teil 7: KI in der Musikproduktion
Peter Tschmuck ist Professor am Institut für Popularmusik (ipop) der mdw.
Endnoten
- Ralf Otte, 2021, Maschinenbewusstsein. Die neue Stufe der KI – wie weit wollen wir gehen? Frankfurt/New York: Campus Verlag, Kindle-Ausgabe Pos. 624-641. ↩︎
- Ibid., Pos. 787-821. ↩︎
- Choi et al., 2020, „Introduction to Machine Learning, Neural Networks, and Deep Learning“, Translational Vision Science & Technology, Vol. 9(4), article 14, S. 3 ↩︎
- Ein Algorithmus ist eine klar definierte Vorgangsweise, wie ein Problem in einzelnen Schritten abgearbeitet werden kann, was in einfachen Wenn-Dann-Sätzen erfolgt. ↩︎
- Siehe Batta Mahesh, 2018, „Machine Learning Algorithms – A Review“, International Journal of Science and Research, Vol. 9(1), S. 381-383. ↩︎
- Ibid., S. 383. ↩︎
- Ibid., S. 384. ↩︎
- Ibid., S. 385. ↩︎
- Im Englischen spricht man von Artificial Neural Networks (ANN). ↩︎
- Choi et al., 2020, „Introduction to Machine Learning, Neural Networks, and Deep Learning“, Translational Vision Science & Technology, Vol. 9(4), article 14, S. 7-9. ↩︎
- Blog des Fraunhofer-Instituts für Arbeitswirtschaft und Organisation, „Spielarten der Künstlichen Intelligenz: Maschinelles Lernen und Künstliche Neuronale Netze“, 24. Mai 2019, Zugriff am 11.09.2023. ↩︎
- Kai-Fu Lee und Qiufan Chen, 2023, KI 2041. Zehn Zukunftsvisionen, Frankfurt und New York: Campus Verlag, S. 50-54. ↩︎
- Ibid., S. 96-98. ↩︎