
Eine wesentliche Weiterentwicklung für ein NutzerInnen-freundliches Musikschaffen sind Text-zu-Musik-Generatoren, über die mit einfachen Befehlen (prompts) die KIs angewiesen werden, welche Musik sie machen sollen, so wie wir es von ChatGPT kennen. Auf diese Weise werden massenhaft nicht nur neue Musikstücke von KIs geschaffen, sondern auch Stimmen-Klone von Superstars angefertigt, die nicht mehr vom Original unterschieden werden können. Die bekanntesten Tools wie Music LM, Stable Audio, Riffusion und MusicGen werden in diesem Teil der Blogserien genauer beschrieben.
Auch den nächsten Schritt im KI-Musikschaffen hat Google bereits gemacht, als im Januar 2023 von einem seiner Forschungsteams der Text-zu-Musik-Generator Music LM in einem wissenschaftlichen Paper vorgestellt wurde.1 Das KI-System ist in der Lage, eine Textanweisung wie z.B. „Schreibe mir eine ruhige Geigenmelodie, unterlegt mit einem verzerrten Gitarrenriff“ in Töne umzusetzen. Es können Melodien gepfiffen oder gesummt werden und die KI kann das Musikstück erkennen und wiedergeben. Im Artikel kann anhand von zahlreichen Musikbeispielen die Leistungsfähigkeit von Music LM nachvollzogen werden. Diese übertrifft bereits existierende Text-zu-Musik-Generatoren wie Riffusion oder Dance Diffusion. Da Google aber sein KI-System mit einer wesentlich größeren Datenmenge trainiert hat, sind die Ergebnisse wesentlich beeindruckender. Die generierte Musik ist klanglich wesentlich komplexer und von hoher akustischer Qualität. Zudem ist das KI-System in der Lage, sogar Bilder wie ein Gemälde von Salvatore Dali in Musik zu übersetzen.2 Allerdings wurde die KI nicht sogleich der Öffentlichkeit zugänglich gemacht, weil bei den 280.000 Stunden Musik, die Music LM für das Training benötigt hat, urheberrechtliche Bedenken aufgekommen sind. Die ForscherInnen haben nämlich festgestellt, dass rund 1 Prozent der von Music LM erzeugten Musik eine direkte Replikation bereits existierender, urheberrechtlich geschützter Songs war.3 Am 10. Mai 2023 wurde Music LM in begrenzter Form in der AI Test Kitchen als App öffentlich zugänglich gemacht, allerdings müssen sich die UserInnen registrieren und in eine Warteliste eintragen sowie zustimmen, dass die von ihnen generierten Daten für das weitere Training der KI verwendet werden dürfen.4
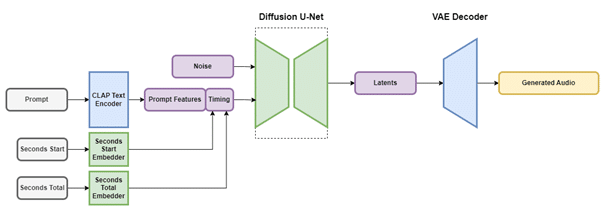
Einen Schritt weiter ist ein anderes KI-Unternehmen, das mit seiner Text-zu-Musik-KI 2023 Furore gemacht hat. Die in London ansässige Firma Stability AI, die mit ihrem KI-Bildgenerator Stable Diffusion große öffentliche Aufmerksamkeit erregt hat, stellte im September 2023 Stable Audio vor. Ein Jahr zuvor hatte Stability AI ohne großes mediales Getöse die Text-zu-Musik-KI Dance Diffusion veröffentlicht, die erstmals in der Lage war, kurze Musikstücke aufgrund von Prompts, also Textanweisungen, zu erstellen.5 Die Leistungsfähigkeit dieser KI war aber begrenzt, sodass Stablility AI mit Stable Audio ein Jahr später nachbessern musste. Im Gegensatz zum Vorläufermodell baut Stable Audio auf rund 1,2 Milliarden Parametern auf und produziert Audiofiles mit hoher klanglicher Qualität auf Basis der latenten Diffusionstechnologie. Diese wird ausführlich auf der Homepage des Unternehmens erklärt.6 Das KI-System besteht demnach aus einem variablen Audio-Encoder, einen Text-Encoder7 und dem Diffusionsmodell. Es wird nicht mit rohen Audio-Samples gearbeitet, sondern mit latent kodierten Audiodateien, die ein schnelleres Training ermöglichen. Dazu wird ein Convolutional Neuronal Network (CNN) verwendet, das mit einem Datensatz von mehr als 800.000 Audiodateien mit Musikstücken, Soundeffekten und einzelnen Audiospuren von Instrumenten sowie Text-Metadaten gefüttert wurde. Die Musikdaten im Umfang von 19.500 Stunden stammen vom Datenanbieter AudioSparx und sind urheberrechtsfrei verfügbar. Ausführlich wird der Trainingsprozess erklärt und wie das Texteingabesystem, CLAP-Modell genannt, funktioniert. Ohne in die technischen Details eingehen zu können, ermöglicht es CLAP, dass die Textmerkmale eines Prompts Informationen beinhaltet, die eine Übertragung in Sound bzw. Musik ermöglicht. Der ganze Prozess wird auch grafisch auf der Homepage dargestellt (Abb. 1).
Abbildung 1: Die Funktionsweise von Stable Audio
Stability AI will mit seinen KI-Systemen in der gleichen Liga wie Google und Microsoft (Open AI) mitspielen, benötigt dazu aber Risikokapital. Sein Gründer und CEO Emad Mostaque verfügt als ehemaliger Hedgefonds-Manager, der an der Universität Oxford Mathematik und Computerwissenschaften studiert hatte, über die nötigen wirtschaftlichen Kenntnisse. 2020 gründete Mostaque Stability AI als Open-Access-Projekt, das im Eigentum seiner MitarbeiterInnen steht und betrieben wird. Im Oktober 2022 investierte ein Konsortium rund um Coatue and Lightspeed Venture Partners US $101 Millionen, um die technische Infrastruktur auszubauen und die KI-Projekte voranzutreiben. Dennoch haben die Finanzgeber nur beschränkte Mitspracherechte und Mostaque kontrolliert weiterhin das Board.8
Eine weiteres KI-Start-up, das den Tech-Konzernen die Stirn bietet, ist Riffusion, das als Spaß-Projekt von den beiden Softwareentwicklern Seth Forsgren und Hayk Martiros 2022 gestartet wurde. Aber anstatt Text oder Bilder in Musik zu verwandeln, schufen sie ein KI-System, dass Musik in Form von Spektrogrammen in Bilder umwandeln konnte.9 Aus dem Spaß wurde bald schon Ernst, als Investoren anklopften, um Riffusion zu kommerzialisieren. Dazu stellte ein Investmentkonsortium aus Greycroft, South Park Commons und Sky9 US $9 Millionen zur Verfügung, die in die Entwicklung einer Text-zu-Musik-KI flossen. Deren Funktionsweise beschrieb Seth Forsgren in einem Interview mit TechCrunch so: „Users simply describe the lyrics and a musical style, and our model generates riffs complete with singing and custom artwork in a few seconds.“.10 Allerdings fehlt Riffusion noch das nötige Kapital, um weiter zu wachsen und es mit den Tech-Giganten aufnehmen zu können.
Über genügend Kapital verfügt hingegen der Facebook-Konzern Meta, der im Juni 2023 den Text-zu-Musik-Generator MusicGen der Öffentlichkeit vorgestellt hat. Im Gegensatz zu Musik LM von Google, ist der Quellcode von MusicGen offengelegt worden, wodurch KI-EntwicklerInnen diesen erweitern und verändern können. MusicGen ist wie Music LM und Stable Audio ein Text-zu-Musik-Generator, der in der Lage ist, auf Basis von Prompts ca. 12-sekündige Musiksamples zu erstellen. Dazu wurde MusicGen mit rund 20.000 Stunden Musik- und Soundfiles trainiert, die von den Mediendatenbankbetreibern ShutterStock und Pond5 lizenziert wurden.11 Im Vergleich ist MusicGen weniger leistungsfähig als die Konkurrenzsysteme von Google und Stability AI, bietet aber eine gute Arbeitsgrundlage für MusikerInnen und ProduzentInnen. Insgesamt kann davon ausgegangen werden, dass MusicGen zu einem der Features im Metaverse ausgebaut wird.
Zusammenfassend lässt sich sagen, dass der Markt von generativer Musik-KI von den großen Tech-Konzernen wie Google (Magenta Studios, WaveNet, MusicLM), Microsoft/Open AI (MuseNet) und Meta (MusicGen) dominiert wird. Es konnten sich aber auch KI-Start-ups wie Stability AI und Riffusion am Markt positionieren, die mit innovativen Ansätzen die Technologiekonzerne herausfordern. Es stellt sich allerdings die Frage, ob diese kleinen Unternehmen auch in der Lage sein werden, genügend Kapitel aufzutreiben, um im Wettlauf mit den Milliarden-Konzernen mithalten zu können. Es könnte durchaus sein, dass ihnen das gleiche Schicksal widerfährt wie den KI-Pionieren DeepMind und Open AI, die schließlich doch von den Tech-Konzernen aufgekauft wurden.
Peter Tschmuck
Dieser Artikel erschien erstmal am 8. April 2024 auf der Seite https://musikwirtschaftsforschung.wordpress.com/2024/04/08/ki-in-der-musikindustrie-teil-13-text-zu-musik-generatoren/
Teil 1: Was ist künstliche Intelligenz?
Teil 2: Wie funktioniert künstliche Intelligenz?
Teil 3: Der Aufstieg von Musikerkennungsdiensten
Teil 4: KI in der Musikerkennung und Musikempfehlung
Teil 5: Die Musikempfehlung im Musikstreaming
Teil 6: Fake-Streams und Streamingfarmen
Teil 7: KI in der Musikproduktion
Teil 8: Maschinen schaffen Musik
Teil 9: Die Vollendung des Unvollendeten
Teil 10: François Pachet: The Continuator, Flow Machines und „Daddy’s Car“
Teil 11: OpenAI und die GPT-Technologie
Teil 12: Googles Magenta Studios und das WaveNet
Peter Tschmuck ist Professor am Institut für Popularmusik (ipop) der mdw.
Endnoten
- Andrea Agostinelli et al., 2023, „MusicLM: Generating Music From Text“, github.io, 28. Januar 2023, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „Google created an AI that can generate music from text descriptions, but won’t release it“, 27. Januar 2023, Zugriff am 07.04.2024. ↩︎
- Ibid. ↩︎
- TechCrunch, „Google makes its text-to-music AI public“, 10. Mai 2023, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „AI music generators could be a boon for artists – but also problematic“, 7. Oktober 2022, Zugriff am 07.04.2024. ↩︎
- Stability AI, „Stable Audio: Fast Timing-Conditioned Latent Audio Diffusion“, 13. September 2023, Zugriff am 07.04.2024. ↩︎
- Encoder sind elektromechanische Geräte, die eine akustische Welle in binäre Codes umwandelt also quasi digitalisiert. Siehe dazu Wikipedia, „Kodierer“, Version vom 23. November 2023, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „Stability AI, the startup behind Stable Diffusion, raises $101M“, 17. Oktober 2023, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „Try ‚Riffusion‘, an AI model that composes music by visualizing it“, 16. Dezember 2022, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „AI-generating music app Riffusion turns viral success into $4M in funding“, 17. Oktober 2023, Zugriff am 07.04.2024. ↩︎
- TechCrunch, „Meta open sources an AI-powered music generator“, 12. Juni 2023, Zugriff am 07.04.2024. ↩︎